基本命令
django-admin.py startproject project_name #新建项目
python manage.py startapp app_name #新建APP
django-admin.py startapp app_name #新建APP
python manage.py makemigrations #创建数据库迁移文件
python manage.py migrate #数据库迁移
python manage.py flush #清空数据库,留下空表
python manage.py runserver [port] #运行服务器
#开发服务器每次更改代码后会自动重启,但由于性能问题不建议用在生产环境
python manage.py createsuperuser #创建超级用户
python manage.py changepassword username #修改密码
python manage.py dumpdata appname > appname.json
python manage.py loaddata appname.json #导入导出数据
python manage.py shell #django终端环境
python manage.py dbshell #数据命令行
python manage.py #查看更多命令
视图与网址
创建项目与应用
django-admin startproject mysite
cd mysite
django-admin startapp learn
tree .
.
├── learn
│ ├── admin.py
│ ├── apps.py
│ ├── __init__.py
│ ├── migrations
│ │ └── __init__.py
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── manage.py
└── mysite
├── __init__.py
├── settings.py #项目设置文件
├── urls.py #url配置文件
└── wsgi.py #与部署到服务器有关
3 directories, 12 files
将app添加到settings.py的INSTALLED_APPS中。这样django能够自动找到app中的模板文件(app_name/templates/下的文件)和静态文件(app_name/static/下的文件)。
定义视图函数
视图基本
编辑learn/views.py:
# coding:utf-8
from django.http import HttpResponse
def index(request):
return HttpResponse(u"欢迎光临 自强学堂!")
我们定义了index()函数,第一个参数必须是 request,与网页发来的请求有关,request 变量里面包含get或post的内容。函数返回了一个 HttpResponse 对象,经过一些处理,最终显示几个字到网页上。
编辑mysite/urls.py:
from django.conf.urls import url
from django.contrib import admin
from learn import views as learn_views # new
urlpatterns = [
url(r'^$', learn_views.index), # new
url(r'^admin/', admin.site.urls),
]
运行服务器即可访问localhost:
python manage.py runserver
视图进阶
编辑musite/urls.py:
from django.conf.urls import url
from django.contrib import admin
from learn import views as learn_views
urlpatterns = [
url(r'^add/$', learn_views.add, name='add'), # 注意修改了这一行
url(r'^admin/', admin.site.urls),
]
在learn/views.py中定义add:
from django.shortcuts import render
from django.http import HttpResponse
def add(request):
a = request.GET['a']
b = request.GET['b']
c = int(a)+int(b)
return HttpResponse(str(c))
request.GET类似一个字典。更好的方式是使用request.GET.get(‘a’,0),当没有传递a时默认a为0.
就可以访问localhost/add/?a=123&b=456这样的url了。如果要采用/add/3/4这样的网址,可以讲urls.py中的URL改为:
url(r'^add/(\d+)/(\d+)/$',learn_views.add, name='add')
其中,(\d+)表示一个或多个数字,括号表示保存为一个子组,每个子组将作为一个参数,被views.py中对应的视图函数接收。然后修改视图中add()函数即可访问localhost/add/3/4:
def add(request, a, b): c = int(a) + int(b) return HttpResponse(str(c))
URL name
我们经常要在网页中引用某个url,比如<a href="/add/4/5/">计算 4+5</a>可以使用前文的加法运算功能。但是,如果因为某些原因,我们需要修改urls.py中的url,那么所有引用该url的代码都要进行修改,非常麻烦。
在urls.py中指定URL name后,可以通过URL name引用网址,引用处会被渲染成urls.py中对应的url。当修改urls.py中的正则表达式部分,只要name不变,其他地方都不需要修改。
在网页模板中,可以如下使用:
不带参数的:
{% url 'name' %}
带参数的:参数可以是变量名
{% url 'name' 参数 %}
例如:
<a href=" {% url 'add' 4 5 %}">link</a>
渲染结果为:
<a href="/add/4/5/">link</a>
在models.py等处可以使用reverse()函数通过url name得到url。如:
from django.urls import reverse
>>> reverse('add2', args=(4,5))
u'/add/4/5/'
另外,如果用户收藏夹中收藏的url是旧的,要跳转到新url的话,可以利用HttpResponseRedirect实现跳转。
Django 模板
访问html文件
在app的views.py中定义home()函数,并设定对应url:
from django.shortcuts import render
def home(request):
return render(request, 'home.html')
在app目录下新建templates目录,在里面新建一个home.html。
<!DOCTYPE html>
<html>
<head><title>欢迎光临</title></head>
<body>欢迎光临自强学堂</body>
</html>
进行数据库迁移后就运行服务器,就可以访问home.html了。
模板的使用
通常,我们做网站有一些通用部分,比如导航、底部、访问统计代码等。可以写一个base.html来包含这些通用文件:
<!DOCTYPE html>
<html>
<head><title> {% block title %}默认标题 {% endblock %} - 自强学堂</title>
</head>
<body>
{% include 'nav.html' %}
{% block content %\
}<div>这里是默认内容,所有继承自这个模板的,如果不覆盖就显示这里的默认内容。</div>
{% block content %\
}<div>这里是默认内容,所有继承自这个模板的,如果不覆盖就显示这里的默认内容。</div>
{% raw %} {% endblock %} {% include 'bottom.html' %}
{% include 'tongji.html' %}
</body>
</html>
继承的模板可以重写block部分,include可以包含其他文件。home.html可以由base.html扩展:
{% extends 'base.html' %}
{% block title %}欢迎光临首页 {% endblock %}
{% block content %}
{% include 'ad.html' %}
这里是首页,欢迎光临
{% endblock %}
Django模板查找机制:Django会查找每个app的templates文件夹,而不仅仅是当前app中的templates文件夹。这样一个app可以使用另一个app的模板,但是当不同app出现同名模板时,有可能会找错模板。可以在templates文件夹下建立一个app同名文件夹,将模板放在app/templates/app/文件夹下。
模板语法
在模板中,可以使用{{}}引用变量,用 {% %}插入语句。
-
显示一个字符串在网页上
# -*- coding: utf-8 -*- # views.py from django.shortcuts import render def home(request): string = u"我在自强学堂学习Django,用它来建网站" return render(request, 'home.html', {'string': string})<!-- home.html --> {{string}}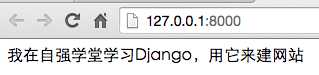
-
for循环和list
# -*- coding: utf-8 -*- # views.py def home(request): TutorialList = ["HTML", "CSS", "jQuery", "Python", "Django"] return render(request, 'home.html', {'TutorialList': TutorialList})<!-- home.html --> {% for i in TutorialList %} {{ i }} {% endfor %}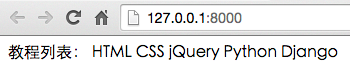
-
字典
# -*- coding: utf-8 -*- # views.py def home(request): info_dict = {'site': u'自强学堂', 'content': u'各种IT技术教程'} return render(request, 'home.html', {'info_dict': info_dict})<!-- home.html --> 站点:{{ info_dict.site }} 内容:{{ info_dict.content }}遍历字典:
<!-- home.html --> {% for key, value in info_dict.items %} {{ key }}: {{ value }} {% endfor %} -
逻辑与比较操作
==,!=,>=,<=,>,<都可以在模板中使用,但前后至少要有一个空格。and,or,not,in,not in也可以在模板中使用。{% if num <= 100 and num >= 0 %} num在0到100之间 {% else %} 数值不在范围之内! {% endif %} -
获取当前网址、当前用户等
待续。
引入静态文件
首先在项目同名文件夹下的setting.py中进行如下设置:
STATIC_URL = '/static/' # 当运行 python manage.py collectstatic 的时候 STATIC_ROOT 文件夹是用来将所有STATICFILES_DIRS中所有文件夹中的文件,以及各app中static中的文件都复制过来.把这些文件放到一起是为了用apache等部署的时候更方便
STATIC_ROOT = os.path.join(BASE_DIR, 'collected_static')
# 其它存放静态文件的文件夹,可以用来存放项目中公用的静态文件,里面不能包含 STATIC_ROOT
# 如果不想用 STATICFILES_DIRS 可以不用,都放在 app 里的 static 中也可以
STATICFILES_DIRS = (
os.path.join(BASE_DIR, "common_static"),
'/path/to/others/static/', # 用不到的时候可以不写这一行
)
# 这个是默认设置,Django 默认会在 STATICFILES_DIRS中的文件夹 和 各app下的static文件夹中找文件注意有先后顺序,找到了就不再继续找了
STATICFILES_FINDERS = (
"django.contrib.staticfiles.finders.FileSystemFinder",
"django.contrib.staticfiles.finders.AppDirectoriesFinder"
)
然后在HTML文件开头加上{% load static %}就可以如下引用:
<link href=" {% static "css/index.css" %}" rel="stylesheet">
<script src=" {% static "js/scrollReveal.js" %}"></script>
Django 模型
基本操作流程
建立数据表
Django使用模型操作数据库。可以修改app/models.py修改数据表:
#people/models.py
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=30)
age = models.IntegerField()
注意,name和age等字段名不能含有__(双下划线)和Python关键字。
接下来同步数据库:
python manage.py makemigrations
python manage.py migrate
操作数据库
python manage.py shell
>>> from people.models import Person
>>> Person.objects.create(name="Mike", age=24)<Person: Person object>
>>> Person.objects.get(name="Mike")<Person: Person object>
这里查询结果都是<Person: Person object>,并没有显示结果的具体信息,可以修改models.py指定显示信息:
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=30)
age = models.IntegerField()
def __unicode__(self): # 在Python3中使用 def __str__(self):
return self.name
此时查询结果变为:
>>> Person.objects.get(name="Mike")
<Person: Mike>
页面引用
模型定义如下:
from django.urls import reverse
class Log(models.Model):
title = models.CharField(max_length=70)
text = RichTextUploadingField()
# reverse()会将url.py中定义的logs路由转换成对应文章的url
# 在html中使用{{ log.get_absolute_url }}引用
def get_absolute_url(self):
return reverse('log_detail', kwargs={'pk': self.pk})
url.py中定义了如下路由:
url(r'^logs/$', blog_views.logs, name='logs'),
url(r'^log/(?P<pk>[0-9]+)/$', blog_views.log_detail, name='log_detail'),
blog_views中对应views如下:
from django.shortcuts import render, get_object_or_404
def logs(request):
log_list = Log.objects.all().
return render(request, 'logs.html', context={'log_list': log_list})
def log_detail(request, pk):
log = get_object_or_404(Log, pk=pk)
return render(request, 'log_detail.html', context={'log':log})
那么host/logs便可以访问文章列表,host/log/2便可以访问第二篇文章。在文章列表也使用可以用get_absolute_url得到相应文章的url。
QuerySet API
从数据库中查询得到的结果一般是一个集合,称为QuerySet。本节例子大部分基于此blog/models.py:
from django.db import models
class Blog(models.Model):
name = models.CharField(max_length=100)
tagline = models.TextField()
def __unicode__(self): # __str__ on Python 3
return self.name
class Author(models.Model):
name = models.CharField(max_length=50)
email = models.EmailField()
def __unicode__(self): # __str__ on Python 3
return self.name
class Entry(models.Model):
blog = models.ForeignKey(Blog)
headline = models.CharField(max_length=255)
body_text = models.TextField()
pub_date = models.DateField()
mod_date = models.DateField()
authors = models.ManyToManyField(Author)
n_comments = models.IntegerField()
n_pingbacks = models.IntegerField()
rating = models.IntegerField()
def __unicode__(self): # __str__ on Python 3
return self.headline
-
创建对象
>>> from blog.models import Blog >>> b = Blog(name='Beatles Blog', tagline='All the latest Beatles news.') >>> b.save() # 总之,一共有四种方法 # 方法 1 Author.objects.create(name="WeizhongTu", email="tuweizhong@163.com") # 方法 2 twz = Author(name="WeizhongTu", email="tuweizhong@163.com")twz.save() # 方法 3 twz = Author()twz.name="WeizhongTu"twz.email="tuweizhong@163.com"twz.save() # 方法 4,首先尝试获取,不存在就创建,可以防止重复 Author.objects.get_or_create(name="WeizhongTu", email="tuweizhong@163.com") # 返回值(object, True/False),创建时返回true,已经存在时返回False -
获取对象
Person.objects.all() # 查询所有 Person.objects.all()[:10] #切片操作,获取10个人,不支持负索引,切片可以节约内存,不支持负索引,后面有相应解决办法,第7条 Person.objects.get(name="WeizhongTu") # 名称为 WeizhongTu 的一条,多条会报错 get是用来获取一个对象的,如果需要获取满足条件的一些人,就要用到filter Person.objects.filter(name="abc") # 等于Person.objects.filter(name__exact="abc") 名称严格等于 "abc" 的人 Person.objects.filter(name__iexact="abc") # 名称为 abc 但是不区分大小写,可以找到 ABC, Abc, aBC,这些都符合条件 Person.objects.filter(name__contains="abc") # 名称中包含 "abc"的人 Person.objects.filter(name__icontains="abc") #名称中包含 "abc",且abc不区分大小写 Person.objects.filter(name__regex="^abc") # 正则表达式查询 Person.objects.filter(name__iregex="^abc")# 正则表达式不区分大小写 # filter是找出满足条件的,当然也有排除符合某条件的 Person.objects.exclude(name__contains="WZ") # 排除包含 WZ 的Person对象 Person.objects.filter(name__contains="abc").exclude(age=23) # 找出名称含有abc, 但是排除年龄是23岁的 -
djang删除数据
Person.objects.filter(name__contains="abc").delete() # 删除 名称中包含 "abc"的人. # 以下两句效果与上面等同,Django实际只执行一条 SQL 语句 people = Person.objects.filter(name__contains="abc") people.delete()。 -
更新内容
# 批量更新 Person.objects.filter(name__contains="abc").update(name='xxx') # 名称中包含 "abc"的人 都改成 xxx Person.objects.all().delete() # 删除所有 Person 记录 # 单独更新 twz = Author.objects.get(name="WeizhongTu") twz.name="WeizhongTu" twz.email="tuweizhong@163.com" twz.save() # 最后不要忘了保存!!! -
QuerySet是可迭代的
es = Entry.objects.all() for e in es: print(e.headline)注意事项:
- 如果只是检查Entry中是否有对象,应该用Entry.objects.all().exists()
- QuerySet支持切片Entry.objects.all()[:10],可以节省内存
- len(es)可以得到Entry的数量,但推荐使用Entry.objects.count(),后者用的是SQL:SELECT COUNT(*)
- list(es)可以将QuerySet变为列表
-
查询结果排序
Author.objects.all().order_by('name') Author.objects.all().order_by('-name') # 在 column name 前加一个负号,可以实现倒序 -
链式查询
Author.objects.filter(name__contains="WeizhongTu").filter(email="tuweizhong@163.com") Author.objects.filter(name__contains="Wei").exclude(email="tuweizhong@163.com") # 找出名称含有abc, 但是排除年龄是23岁的 Person.objects.filter(name__contains="abc").exclude(age=23) -
QuerySet不支持负索引
Person.objects.all()[:10] # 切片操作,前10条 Person.objects.all()[-10:] # 会报错!!! # 1. 使用 reverse() 解决 Person.objects.all().reverse()[:2] # 最后两条 Person.objects.all().reverse()[0] # 最后一条 # 2. 使用 order_by,在栏目名(column name)前加一个负号 Author.objects.order_by('-id')[:20] # id最大的20条 -
QuerySet去重
一般情况下,QuerySet不会出现重复。但当跨越多张表进行检索后,结果拼接后可能重复,可以使用distinct()去重:
qs1 = Pathway.objects.filter(label__name='x') qs2 = Pathway.objects.filter(reaction__name='A + B >> C') qs3 = Pathway.objects.filter(inputer__name='WeizhongTu') # 合并到一起 qs = qs1 | qs2 | qs3 # 这个时候就有可能出现重复的,去重: qs = qs.distinct()
对于从文章列表页到文章详情页的跳转,可以在定义文章model时添加以下函数:
from django.urls import reverse
class Log(models.Model):
title = models.CharField(max_length=70)
text = RichTextUploadingField()
def __str__(self):
return self.title
# reverse()会将url.py中定义的logs路由转换成对应文章的url
# 在html中使用{{ log.get_absolute_url }}引用
def get_absolute_url(self):
return reverse('logs', kwargs={'pk': self.pk})
def log(request, pk):
log = get_object_or_404(Log, pk=pk)
return render(request, 'log.html', context={'log':log})
Django 后台
model定义完毕后,同步数据表并创建super user:
python manage.py makemigrations
python manage.py migratep
ython manage.py createsuperuser
在应用的admin.py中加入:
from .models import Article
admin.site.register(Article)
登录host/admin就可以操作Article表了。但是只显示一个字段(__str__(self)方法定义的字段),如下可以显示更多字段:
from django.contrib import admin
from .models import Article
class ArticleAdmin(admin.ModelAdmin):
list_display = ('title','pub_date','update_time',)
admin.site.register(Article,ArticleAdmin)
ckeditor
博客文章等的排版可以使用ckeditor。在Django中使用ckeditor步骤如下:
-
安装
pip3 install django-ckeditor pip3 install Pillow -
在setting.py中添加到INSTALLED_APPS中:
INSTALLED_APPS = ( ... 'ckeditor', 'ckeditor_uploader' ) -
在settings.py里设置ckeditor的文件上传路径(在此之前需要配置MEDIA_URL和MEDIA_ROOT)。
CKEDITOR_UPLOAD_PATH = "ckupload" -
在settings.py里进行ckeditor的相关配置。
CKEDITOR_CONFIGS = { 'awesome_ckeditor':{ 'toolbar': 'Basic', }, 'default_ckeditor':{ 'toolbar': 'Full', }, } -
在urls.py里配置ckeditor相关的url。
urlpatterns = [ ... url(r'^ckeditor/', include('ckeditor_uploader.urls')), ] -
在models.py中使用:
from ckeditor.fields import RichTextField instructions = RichTextField() # RichTextField拥有TextField的全部参数 learn = RichTextField(config_name='default_ckeditor')
CSRF 认证
使用Ajax交换数据会遇到csrf问题,此时,可以先:
from django.views.decorators.csrf import csrf_exempt
然后在需要使用Ajax交换数据的函数前加上@csrf_exempt:
from django.http import HttpResponse
from django.views.decorators.csrf import csrf_exempt
import json
@csrf_exempt
def encode(request): # 获得前端传过来的json
res = json.loads(request.body)
# do something
return HttpResponse(json.dumps(res,ensure_ascii=False),content_type="application/json,charset=utf-8")
CORS
res = {}
res["content"] = "test"
response = HttpResponse(json.dumps(res,ensure_ascii=False),content_type="application/json,charset=utf-8")
response["Access-Control-Allow-Origin"] = "*"
response["Access-Control-Allow-Methods"] = "POST, GET, OPTIONS"
response["Access-Control-Max-Age"] = "1000"
response["Access-Control-Allow-Headers"] = "*"
return response
获取请求参数
参见 https://www.cnblogs.com/chichung/p/9873425.html
本文由 晓楼 创作,采用 知识共享署名4.0 国际许可协议进行许可。本站文章除注明转载/出处外,均为本站原创或翻译,转载前注明出处