《视觉SLAM十四讲》笔记,感谢高翔先生的付出
第1讲 前言
SLAM: Simultaneous Localization and Mapping,中文译作“同时定位与地图构建”。指搭载特定传感器的主体,在没有环境先验信息的情况下,于运动过程中建立环境的模型,同时估计自己的运动。如果这里的传感器主要为相机,那就称为“视觉 SLAM”。
第2讲 初识SLAM
2.1 相机简介
2.1.1 单目相机
无法通过单张图片得到深度信息。通过移动相机后多张图片上的视差,可以估计相机的运动。但估计的轨迹和地图,将与真实的轨迹和地图,相差一个因子,也就是所谓的尺度(Scale)。由于单目 SLAM 无法仅凭图像确定这个真实尺度,所以又称为尺度不确定性。
优点是结构简单成本低。缺点在于,平移之后才能计算深度,以及无法确定真实尺度。
2.1.2 双目相机
两个单目相机组成,两个相机之间的距离(称为基线,Baseline)是已知的。双目相机测量到的深度范围与基线相关。基线距离越大,能够测量到的就越远。
双目相机既可以应用在室内,亦可应用于室外。双目或多目相机的缺点是配置与标定均较为复杂,其深度量程和精度受双目的基线与分辨率限制,而且视差的计算非常消耗计算资源,需要使用 GPU 和 FPGA 设备加速后,才能实时输出整张图像的距离信息。
2.1.3 深度相机(RGB-D相机)
通过红外结构光或 Time-of-Flight(ToF)原理,通过主动向物体发射光并接收返回的光,测出物体离相机的距离。
相比于双目可节省大量的计算量。但多数 RGB-D 相机还存在测量范围窄、噪声大、视野小、易受日光干扰、无法测量透射材质等诸多问题,在 SLAM 方面,主要用于室内 SLAM,室外则较难应用
2.2 经典视觉 SLAM 框架
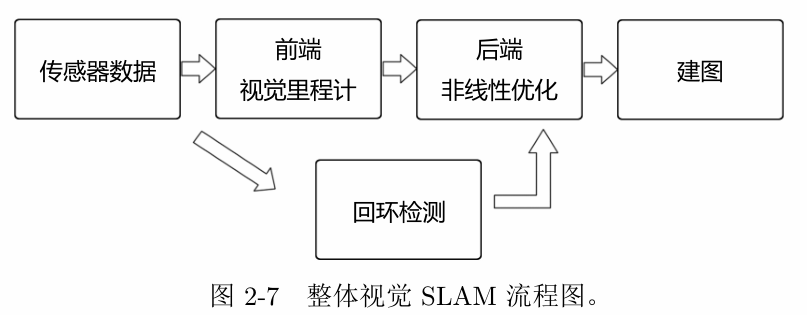
2.2.1 视觉里程计(Visual Odometry, VO)
视觉里程计任务是估算相邻图像间相机的运动,以及局部地图的样子。VO 又称为前端(Front End)。
叫它为“里程计”是因为它和实际的里程计一样,只计算相邻时刻的运动,而和再往前的过去的信息没有关联。
只要把相邻时刻的运动“串”起来,就构成了机器人的运动轨迹,从而解决了定位问题。另一方面,我们根据每个时刻的相机位置,计算出各像素对应的空间点的位置,就得到了地图。但仅通过视觉里程计来估计轨迹,将不可避免地出现累计漂移(Accumulating Drift)。
2.2.2 后端优化(Optimization)
后端接受不同时刻视觉里程计测量的相机位姿,以及回环检测的信息,对它们进行优化,得到全局一致的轨迹和地图。由于接在 VO 之后,又称为后端(Back End)。
2.2.3 回环检测
又称闭环检测(Loop Closure Detection)。回环检测判断机器人是否曾经到达过先前的位置。如果检测到回环,它会把信息提供给后端进行处理。主要解决位置估计随时间漂移的问题。
2.2.4 建图
根据估计的轨迹,建立与任务要求对应的地图。地图的形式随 SLAM 的应用场合而定。大体上讲,可以分为度量地图与拓扑地图两种。
度量地图(Metric Map)
强调精确地表示地图中物体的位置关系,通常我们用稀疏(Sparse)与稠密(Dense)对它们进行分类。
稀疏地图进行了一定程度的抽象,并不需要表达所有的物体。选择一部分具有代表意义的东西,称之为路标(Landmark),稀疏地图就是由路标组成的地图。
稠密地图通常按照某种分辨率,由许多个小块组成。二维度量地图是许多个小格子(Grid),三维则是许多小方块(Voxel)。一般地,一个小块含有占据、空闲、未知三种状态,以表达该格内是否有物体。这样的地图可以用于各种导航算法,如 A*,D*等。
稠密地图需要存储每一个格点的状态,耗费大量的存储空间,多数情况下地图的许多细节部分是无用的。另一方面,大规模度量地图有时会出现一致性问题。很小的一点转向误差,可能会导致两间屋子的墙出现重叠,使得地图失效。
拓扑地图(Topological Map)
拓扑地图则更强调地图元素之间的关系。拓扑地图是一个图(Graph),由节点和边组成,只考虑节点间的连通性,而不考虑如何从 A 点到达 B 点的过程。
2.3 SLAM 问题的数学表述
\[\begin{equation} \begin{cases} \boldsymbol{x}_k = f(\boldsymbol{x}_{k-1}, \boldsymbol{u}_k, \boldsymbol{w}_k) \\ \boldsymbol{z}_{k,j} = h(\boldsymbol{y}_j, \boldsymbol{x}_k, \boldsymbol{v}_{k,j}) \end{cases} \end{equation}\]$\boldsymbol{x}_k$: k时刻机器人的位置
$\boldsymbol{u}_k$: 运动传感器的读数(有时也叫输入)
$\boldsymbol{w}k$, $\boldsymbol{v}{k,j}$: 噪声
运动方程:机器人根据上一时刻的位置和本时刻的传感器读数,得到本时刻的位置
观测方程:机器人在位置 $\boldsymbol{x}k$ 看到路标 $\boldsymbol{y}_j$,产生一个观测数据$\boldsymbol{z}{j,k}$。
SLAM 问题:当我们知道运动测量的读数 $\boldsymbol{u}$,以及传感器的读数 $\boldsymbol{z}$ 时,如何求解定位问题(估计 $\boldsymbol{x}$)和建图问题(估计 $\boldsymbol{y}$)?这时,我们把 SLAM 问题建模成了一个状态估计问题:如何通过带有噪声的测量数据,估计内部的、隐藏着的状态变量.
按照运动和观测方程是否为线性,噪声是否服从高斯分布进行分类,分为线性/非线性和高斯/非高斯系统。其中线性高斯系统(Linear Gaussian, LG 系统)是最简单的,它的无偏的最优估计可以由卡尔曼滤波器(Kalman Filter, KF)给出。而在复杂的非线性非高斯系统(Non-Linear Non-Gaussian,NLNG 系统)中,我们会使用以扩展卡尔曼滤波器(Extended Kalman Filter, EKF)和非线性优化两大类方法去求解它.
位姿(Pose):位置与姿态,包含了旋转(Rotation)和平移(Trans-lation)。
第3讲 三维空间的刚体运动
一个刚体在三维空间中的运动由一次旋转加一次平移组成。平移比较好描述,本章主要介绍如何描述旋转。
3.1 旋转矩阵
相机是运动的,通常我们会设定一个惯性坐标系(或者叫世界坐标系),认为它是固定不动的。
相机坐标系中的某个向量$p$, 其坐标为$p_c$, 在世界坐标系下,其坐标为$p_w$。这二者如何转换呢?
相机运动是一个刚体运动,它保证了同一个向量在各个坐标系下的长度和夹角都不会发生变化。这种变换称为欧氏变换。在欧式变换中,一个向量$\boldsymbol{a}$经过一次旋转得到$\boldsymbol{a}’$,可以通过乘上旋转矩阵 $R$ 来实现,而平移只是加上一个向量。因此欧氏空间的坐标变换关系可以用下式表示:
\[\begin{bmatrix} \boldsymbol{a}' \\ 1 \end{bmatrix} = \begin{bmatrix} \boldsymbol{R} & \boldsymbol{t} \\ \boldsymbol{0}^{T} & 1 \end{bmatrix} \begin{bmatrix} \boldsymbol{a} \\ 1 \end{bmatrix} \triangleq \boldsymbol{T} \begin{bmatrix} \boldsymbol{a} \\ 1 \end{bmatrix}\]这样就把旋转和平移写在了一个矩阵里面,使得整个关系变成了线性关系。该式中,矩阵 $T$ 称为变换矩阵(Transform Matrix)。
3.2 实践:Eigen
略
3.3 旋转向量和欧拉角
3.3.1 旋转向量
转矩阵有九个量,但一次旋转只有三个自由度。因此这种表达方式是冗余的。同样的,变换矩阵用十六个量表达了旋转加平移六自由度的变换。
任意旋转都可以用一个旋转轴和一个旋转角来刻画。于是,我们可以使用一个向量,其方向与旋转轴一致,而长度等于旋转角。这种向量,称为旋转向量(或轴角,Axis-Angle)。同样,对于变换矩阵,我们使用一个旋转向量和一个平移向量即可表达一次变换。这时的维数正好是六维。
由旋转向量到旋转矩阵的变换由罗德里格斯公式(Rodrigues’s Formula )给出,略。
3.3.2 欧拉角
旋转矩阵、旋转向量,对人类是非常不直观的。我们看到一个旋转矩阵或旋转向量时,很难想象出来这个旋转究竟是什么样的。欧拉角则提供了一种非常直观的方式来描述旋转——它使用了三个分离的转角,把一个旋转分解成三次绕不同轴的旋转。
欧拉角当中比较常用的一种,是用“偏航-俯仰-滚转”(yaw-pitch-roll)三个角度来描述一个旋转的。它等价于 ZYX 轴的旋转。
欧拉角的一个重大缺点是会碰到著名的万向锁问题(Gimbal Lockx):在俯仰角为 $\pm90\degree$◦ 时,第一次旋转与第三次旋转将使用同一个轴,使得系统丢失了一个自由度(由三次旋转变成了两次旋转)。这被称为奇异性问题。理论上可以证明,只要我们想用三个实数来表达三维旋转时,都会不可避免地碰到奇异性问题。
3.4 四元数
四元数(Quaternion)是一种扩展的复数。用它描述三维向量的旋转,既是紧凑的,也没有奇异性。一个四元数 $\boldsymbol{q}$ 拥有一个实部和三个虚部:
\[\boldsymbol{q} = q_0+q_{1}i+q_2j+q_3k\]三个虚部满足关系式:
\[\begin{equation} \begin{cases} i^2 = j^2 = k^2 = -1 \\ ij = k, ji = -k \\ jk = i, kj = -i \\ ki = j, ik = -j \end{cases} \end{equation}\]也可以用一个标量和一个向量来表达四元数:
\[\boldsymbol{q} = [s, \boldsymbol{v}], \quad s=q_0 \in \mathbb{R}, \boldsymbol{v} = [q_1,q_2,q_3]^T \in \mathbb{R}^3\]四元数能够表达三维空间的旋转。这种表达方式和旋转矩阵、旋转向量之间可以相互转换,具体略。
第4讲 李群与李代数
略
第5讲 相机与图像
5.1 相机模型
5.1.1 针孔相机模型
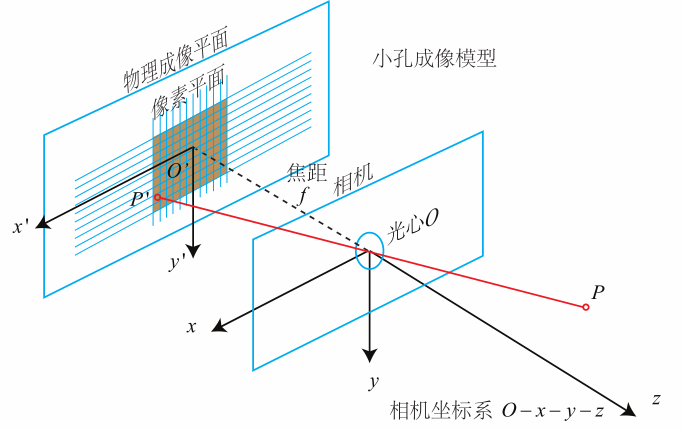
设P在相机坐标系下的坐标为 $[X,Y,Z]^T$,在像素坐标系下的坐标记为 $ [u,v]^T$,那么有: \(Z \begin{pmatrix} u \\ v \\ 1 \end{pmatrix} = \begin{pmatrix} f_x & 0 & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1 \end{pmatrix} \begin{pmatrix} X \\ Y \\ Z \end{pmatrix} \triangleq \boldsymbol{KP}\) 矩阵 $K$ 称为相机的内参数矩阵,在出厂之后是固定的,不会在使用过程中发生变化。
像素坐标系与成像平面之间,相差了一个缩放和一个原点的平移。$K$ 中的 $c_x, c_y$ 是原点的平移量,$f_x, f_y$ 是两个坐标轴方向的缩放倍数乘以焦距。因此 $K$ 只与相机本身相关。
如果知道相机的位姿 $\boldsymbol{R}, \boldsymbol{t}$ ,那么点 $P$ 在世界坐标系下的坐标可以转换为像素坐标: \(Z\boldsymbol{P}_{uv}=Z \begin{bmatrix} u \\ v \\1 \end{bmatrix} =\boldsymbol{K}(\boldsymbol{R}\boldsymbol{P}_w+\boldsymbol{t}) =\boldsymbol{K}\boldsymbol{T}\boldsymbol{P}_w\)
齐次坐标乘上非零常数后表达同样的含义,所以上式可以简单地把 $Z$ 去掉
相对于内参,将相机相对世界坐标系的位姿 $\boldsymbol{R}, \boldsymbol{t}$ 称为相机的外参数。
5.1.2 畸变
由透镜形状引起的畸变称之为径向畸变,又分为桶形畸变和枕形畸变。
相机的组装过程中由于不能使得透镜和成像面严格平行,会引入切向畸变。
5.1.3 双目相机模型
从针孔相机模型可以看出,从点P到光心O的连线上的所有点,都投影到了同一个点,因此单目相机无法确定深度信息。
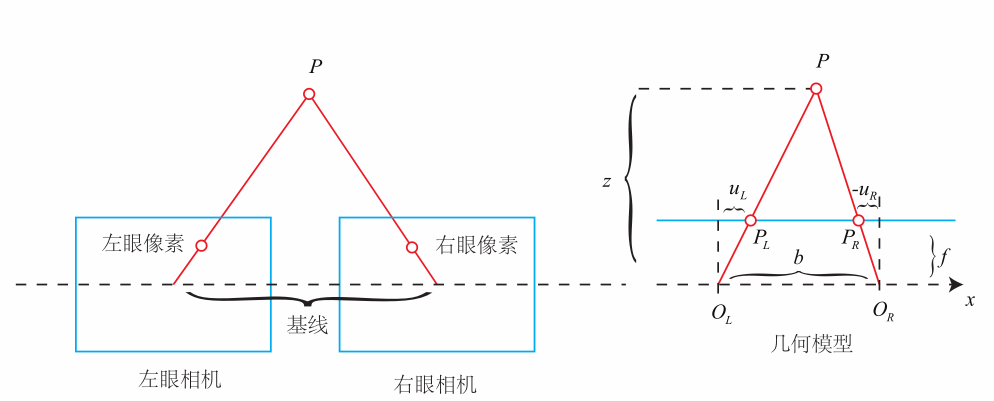
从上图可以看出,每个相机确定了一条线,两条线的交点就是 $P$ 的实际位置。因此双目相机可以得到深度信息。两个相机光心间的距离 $b$ (称为双目相机的基线,Baseline)是已知的,那么有: \(z=\frac{fb}{d}, \quad d = u_L - u_R\) $d$ 为左右图的横坐标之差,称为视差(Disparity)。视差与距离成反比,视差越大,距离越近。
由于视差最小为一个像素,于是双目的深度存在一个理论上的最大值,由 $fb$ 确定。当基线越长时,双目最大能测到的距离就会变远;反之,小型双目器件则只能测量很近的距离。
视差计算深度公式很简洁,但视差本身的计算却比较困难。我们需要确切地知道左眼图像某个像素出现在右眼图像的哪一个位置(即对应关系),这件事亦属于“人类觉得容易而计算机觉得困难”的事务。当我们想计算每个像素的深度时,其计算量与精度都将成为问题,而且只有在图像纹理变化丰富的地方才能计算视差。
5.1.4 RGB-D 相机模型
RGB-D 相机按原理可分为两大类:
- 通过红外结构光(Structured Light)来测量像素距离的
- 通过飞行时间法(Time-of-flight, ToF)原理测量像素距离的
ToF 原理和激光传感器十分相似,不过激光是通过逐点扫描来获取距离,而 ToF 相机则可以获得整个图像的像素深度。
在测量深度之后,RGB-D 相机通常按照生产时的各个相机摆放位置,自己完成深度与彩色图像素之间的配对,输出一一对应的彩色图和深度图。我们可以在同一个图像位置,读取到色彩信息和距离信息,计算像素的 3D 相机坐标,生成点云(Point Cloud)。
5.2 图像
略
5.3 实践:图像的存取与访问
略
5.4 实践:拼接点云
本节程序提供了五张 RGB-D 图像,并且知道了每个图像的内参和外参。我们可以计算任何一个像素在相机坐标系下的位置。同时,根据相机位姿,又能计算这些像素在世界坐标系下的位置。如果把所有像素的空间坐标都求出来,相当于构建了一张类似于地图的东西。
第6讲 非线性优化
略
第7讲 视觉里程计1
视觉里程计(VO)根据相邻图像的信息,估计出粗略的相机运动,给后端提供较好的初始值。VO 的实现方法,按是否需要提取特征,有特征点法以及不提特征的直接法。特征点法运行稳定,对光照、动态物体不敏感,是目前比较成熟的解决方案。
7.1 特征点法
7.1.1 特征点
特征点法首先从图像中选取比较有代表性的点。这些点在相机视角发生少量变化后会保持不变,所以我们会在各个图像中找到相同的点。然后,在这些点的基础上,讨论相机位姿估计问题,以及这些点的定位问题。在经典 SLAM 模型中,把这些点称为路标。而在视觉 SLAM 中,路标则是指图像特征(Features)。
特征点由关键点(Key-point)和描述子(Descriptor)两部分组成。关键点是指该特征点在图像里的位置,有些特征点还具有朝向、大小等信息。描述子通常是一个向量,按照某种人为设计的方式,描述了该关键点周围像素的信息。描述子是按照“外观相似的特征应该有相似的描述子”的原则设计的。因此,只要两个特征点的描述子在向量空间上的距离相近,就可以认为它们是同样的特征点。
7.1.2 ORB 特征
ORB(Oriented FAST and Rotated BRIEF) 特征亦由关键点和描述子两部分组成。它的关键点称为“Oriented FAST”,是一种改进的 FAST 角点,它的描述子称为 BRIEF。
FAST 关键点主要是检测局部像素灰度变化,如果一个像素与它邻域的像素差别较大(过亮或过暗), 那它更可能是角点。ORB 对原始 FAST的优化主要是限定了角度数量、添加了尺度和旋转的描述。
BRIEF 是一种二进制描述子,它的描述向量由许多个 0 和 1 组成,编码了关键点附近一些像素的大小关系。这些像素按照某种概率分布,随机地挑选。原始的 BRIEF 描述子不具有旋转不变性的,因此在图像发生旋转时容易丢失。而 ORB 在 FAST 特征点提取阶段计算了关键 点的方向,所以可以利用方向信息,计算了旋转之后的“Steer BRIEF”特征,使 ORB 的描述子具有较好的旋转不变性。
7.1.3 特征匹配
对于两张图片中的特征点,分别计算特征点描述子间的距离,距离近的认为是同一个特征点。
特征点数量巨大,如果暴力匹配,计算量巨大。快速近似最近邻(FLANN)算法更加适合于匹配点数量极多的情况。
7.2 实践:特征提取和匹配
略
7.3 2D-2D:对极几何
根据匹配的特征点对,估计相机的运动。这里由于相机的原理不同,情况发生了变化:
-
当相机为单目时,我们只知道 2D 的像素坐标,因而问题是根据两组 2D 点估计运动。该问题用对极几何来解决。
- 当相机为双目、RGB-D 时,或者通过某种方法得到了距离信息,那就是根据两组 3D 点估计运动。该问题通常用 ICP 来解决。
- 如果有 3D 点和它们在相机的投影位置,也能估计相机的运动。该问题通过 PnP 求解。
假设我们通过特征点匹配,找到了同一个空间点在相机两个不同时刻的成像点,其像素坐标为 $p_1, p_2$。那么有: \(\boldsymbol{E} = \boldsymbol{t}^\land \boldsymbol{R}, \quad \boldsymbol{F} = \boldsymbol{K}^{-T}\boldsymbol{E}\boldsymbol{K}{-1}, \quad \boldsymbol{x}_2^T\boldsymbol{E}\boldsymbol{x}_1=\boldsymbol{p}_2^T\boldsymbol{F}\boldsymbol{p}_1=0\) 其中: \(\boldsymbol{x}_1 = \boldsymbol{K}^{-1}\boldsymbol{p}_1, \quad \boldsymbol{x}_2 = \boldsymbol{K}^{-1}\boldsymbol{p}_2\) 推导见原书。上面最后两个等于0的式子都称为对极约束。称 $\boldsymbol{F}$ 为基础矩阵,$\boldsymbol{E}$ 为本质矩阵。如果相机内参 $\boldsymbol{K}$ 已知,那么他们只和相机的运动有关。根据对极约束,给定足够多的特征点,那么我们就可以建立方程求解出 $\boldsymbol{E}$ 或 $\boldsymbol{F}$,进而求出相机的运动。实践当中往往使用形式更简单的 $\boldsymbol{E}$。
最少使用5个特征点即可求出 $\boldsymbol{E}$,但计算量大。通常使用八个点(八点法)
7.4 实践:对极约束求解相机运动
略
7.5 三角测量
使用对极几何得到运动之后,下一步我们需要用相机的运动估计特征点的空间位置。按理说,我们得到了相机的运动,那么相机两次图像间的关系,就类似于双目相机了,我们可以像双目相机那样推导深度信息。但不幸的是,由于噪声等因素,我们对相机运动的估计不可能完全正确。
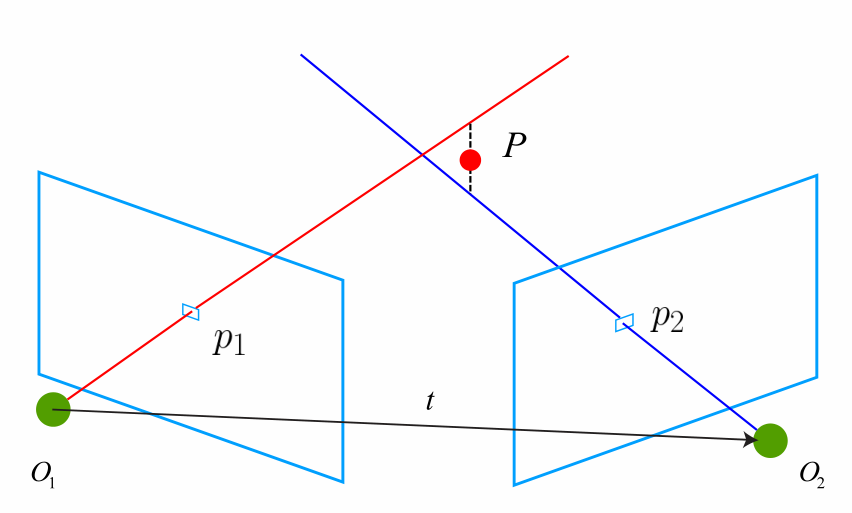
如上图,我们关心的两条线甚至不会相交与一点。此时我们可以通过最二小乘去求解一个相对合理的P。具体过程参考原书,反正能解。
7.6 ~ 7.11
主要介绍 3D-2D, 3D-3D 情况下运动的估计,具体参考原书。
第8讲 视觉里程计2
主要介绍直接法。直接法基于灰度不变假设:同一个空间点的像素灰度值,在各个图像中是固定不变的。这个假设太强了。本章内容不多,略去吧。需要时直接参考原书。
第9讲 实践章:设计前端
帧:一个帧是相机采集到的图像单位。它主要包含一个图像(RGB-D 情形下是一对图像)。此外,还有特征点、位姿、内参等信息。
关键帧(Key-frame):相机采集的数据很多,存储所有的数据显然是不现实的(如果相机放在桌上不动,程序的内存占用也会越来越高最后导致无法接受)。通常的做法是把某些我们认为更重要的帧保存起来,并认为相机轨迹就可以用这些关键帧来描述。
常见的做法时,每当相机运动经过一定间隔,就取一个新的关键帧并保存起来。这些关键帧的位姿将被仔细优化,而位于两个关键帧之间的那些东西,除了对地图贡献一些地图点外,就被忽略掉了。
路标:路标点即图像中的特征点。当相机运动之后,我们还能估计它们的 3D 位置。通常,会把路标点放在一个地图当中,并将新来的帧与地图中的路标点进行匹配,估计相机位姿。
第10讲 后端1
第11讲 后端2
这两讲公式较多,没有摘抄记录的必要,需要的时候看原书吧。
第12讲 回环检测
主要介绍词袋模型(BoW),和机器学习里没有太大区别,略。
第13讲 建图
主要介绍各种地图,需要时看原书吧。
第14讲 SLAM:现在与未来
略
本文由 晓楼 创作,采用 知识共享署名4.0 国际许可协议进行许可。本站文章除注明转载/出处外,均为本站原创或翻译,转载前注明出处